
先說結論
- 若只存英文、數字...等鍵盤上會出現的字的話,可以用
utf8_general_ci(但不推廌) - 若會存中文、德文...等非英文的字、或存 Emoji 的話,建議用
utf8mb4_unicode_ci
utf8mb4 vs. utf8
在 MySQL 5.5.3 以後,一般來說會建議用 utf8mb4。因為它才是真正的 UTF-8 編碼,且完全兼容 utf8。 utf8 速度比較快但只支援三個字元長度的字,這代表部份中文字以及 Emoji 要存入的時候會噴錯。因為 utf8 這個名字實在是太令人混淆了,很多人會誤以為它就是 UTF-8 編碼,因此後來官方也做了一些調整,將它改名為 utf8mb3,mb3 指的是用三個位元組儲存,mb4 則是用四個位元組儲存的意思。
到了 MySQL 8.0 時, Oracle 將 utf8mb4 設為了預設編碼,也做了大幅的效能優化,變得比 utf8mb3 快很多,因此再也沒有使用舊編碼的理由了,舊編碼也被官方標為 deprecated,在未來會被移除掉。效能優化如下圖所示:(紅線為 mb4,Y 軸為每秒 transactions 數量 )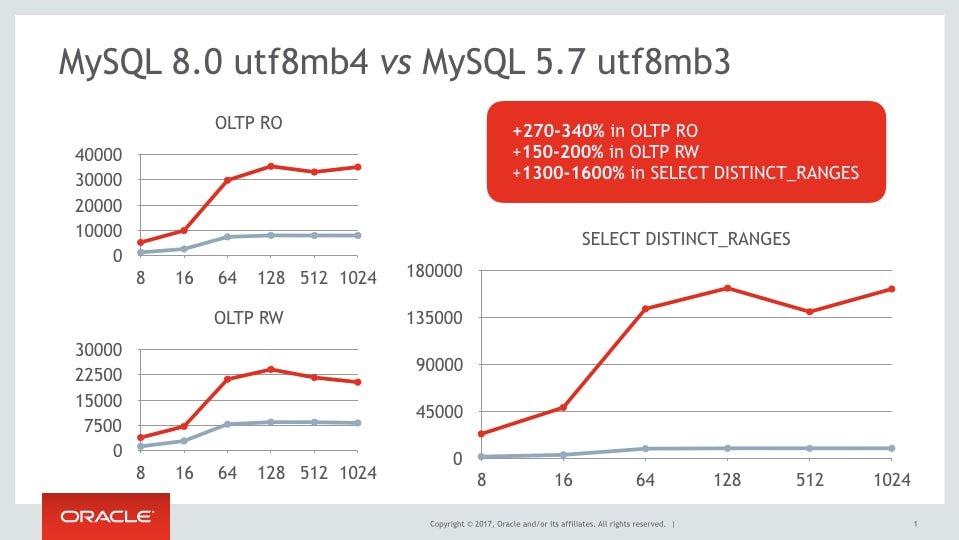
ci vs. bin vs. cs
這三者就要看需求而定
ci是指 case-insensitive,例如 utf8mb4_unicode_ci 是不分大小寫的cs是指 case-sensitive,例如 utf8mb4_unicode_cs 是會區分大小寫的bin會用 binary value 比對,例如 utf8mb4_bin 會區分大小寫的且也會區分Ä和A的不同
通常預設會用 _ci 結尾、不分大小寫的編碼 ,如果有需求的話,再看要改用其它哪個編碼。
general vs. unicode
一般會建議用 unicode,不要用 general 的版本。
general版本(例如 utf8mb4_general_ci),在排序時比較快,但在某些特殊情況會排錯。unicode版本(例如 utf8mb4_unicode_ci),實作了完整的 Unicode 標準。
例如在德文的 ß 在排序時應該看作是 ss,但在 _general_ci 內會被當成 s。或是有些字元是隱藏字元,排序時不應該被拿來做計算之類的。中文字之間的排序可能也會不一樣。詳細差別可以參考「官方文件」中的說明。
benchmark
效能上的差異大概是:
- where column = ? 時,unicode 慢 3-10%
- where column like ? 時,unicode 慢 4-12%
- order by column 時,unicode 慢 8%
(reference))
效能差距不大,為了保險起見用 unicode 比較不會遇到問題。除非有特殊需求或效能上的考量,再來考慮 general 的版本。但也有可能會因為 MySQL 新版本的優化,導致速度差異有變化,建議還是自己做一下 benchmark 評估看看要不要用 general 比較好。
